![[자료구조] 스택, 큐, 힙](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FSSIz9%2FbtqSKNoKjaH%2FAAAAAAAAAAAAAAAAAAAAANsCzF56jDPNq-nc21gSJE5VYJwgbSTp2S19ahpSMddz%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DxGeQFGDsyBamn3bxEvcypYYIKbs%253D)
반응형
스택
스택의 개념
- 선형 자료구조의 일종
- Last In First out(LIFO) 구조
- 차곡차곡 쌓이는 구조
- 나중에 들어간 원소가 먼저 나온다.
스택의 특징
- 같은 구조의 같은 크기의 자료를 정해진 방향으로만 쌓을 수 있고, top으로 정한 곳을 통해서만 접근 가능하다.
- 삭제는 top을 통해서만 가능하다.
스택의 연산
- 삭제 (pop()) : 스택에서 가장 위에 있는 항목을 제거한다. [O(1)]
- 삽입 (push(item)) : item 하나를 스택의 가장 윗부분에 추가한다. [O(1)]
- 읽기 (peek()) : 스택의 가장 위에 있는 항목을 반환한다. [O(1)]
스택 포인터(SP, Stack Pointer)
- push나 pop을 할 때 해당 값의 위치를 알고 있어야 하는데 스택 포인터가 위치를 기억한다.
- 처음 기본값은 -1
- ex) push
- ex) pop
스택의 활용 예시
- 웹 브라우저 방문기록 (뒤로 가기) : 가장 나중에 열린 페이지부터 다시 보여준다.
- 역순 문자열 만들기 : 가장 나중에 입력된 문자부터 출력한다.
- 실행 취소 (undo) : 가장 나중에 실행된 것부터 실행을 취소한다.
- 후위 표기법 계산
- 재귀함수
큐
큐의 개념
- 선형 자료구조의 일종
- FIrst In First Out(FIFO) 구조
- 먼저 들어간 원소가 먼저 나온다.
- 먼저 들어간 원소가 맨 앞에서 대기하고 있다가 먼저 나오게 되는 구조
- Java Collection에서 Queue는 인터페이스다.
큐의 특징
- 가장 첫 원소를 front, 끝 원소를 rear라고 부른다.
- 가장 첫 원소와 끝 원소로만 접근 가능하다.
큐의 연산
- 삽입 (Enqueue()) : 큐 맨 뒤에 어떠한 요소를 추가 [O(1)]
- 삭제 (Dequeue()) : 큐 맨 앞쪽의 요소를 삭제 [O(1)]
- 읽기 (peek()) : front에 위치한 데이터를 읽음 [O(n)]
Front와 rear
- 데이터를 넣고 뺄 때 해당 값의 위치를 기억해야 한다. (스택 포인터와 같은 역할)
- front : 큐의 맨 앞의 위치(인덱스)를 본다.
- rear : 큐의 맨 뒤의 위치(인덱스)를 본다.
선형 큐의 문제점
- 큐에 데이터가 꽉 차면 데이터를 더 추가할 수 없다.
- 선형 큐에서 삽입 및 삭제를 반복하다 보면, rear가 맨 마지막 인덱스를 가리키고, 앞에는 비어 있을 수 있지만 이를 꽉 찼다고 인식합니다.
(rear가 배열의 마지막 위치에 있기 때문에 큐에 빈자리가 있는데도 포화 상태로 인식하고 삽입 연산을 수행하지 않는다.)
- 실제 데이터는 삭제 때마다 한 칸 앞으로 이동시키지 않았고, 인덱스 단위로 큐 연산을 진행했기 때문이다.
- 이를 방지하기 위해 **원형 큐(Circular Queue)**가 존재한다.
원형큐
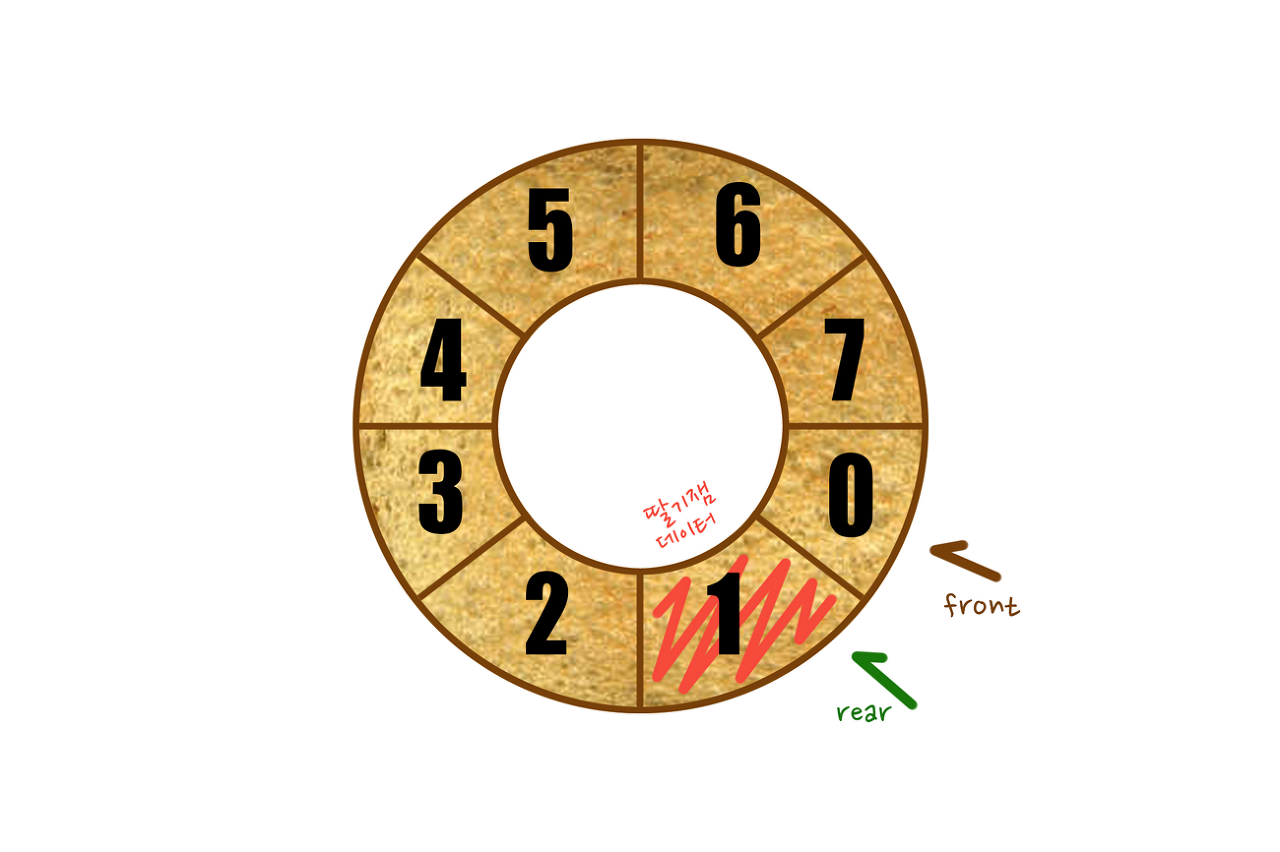
- 논리적으로 배열의 처음과 끝이 연결되어 있는 것으로 간주한다.
- 초기 공백 상태일 때 front와 rear가 0
- 공백, 포화 상태를 쉽게 구분하기 위해 자리 하나를 항상 비워둔다.(사이즈+1)
- 데이터 추가 시 rear가, 삭제 시 front가 1칸 움직입니다.

- rear = (rear + 1) % size 만큼 움직입니다.
- rear가 7일 때, 공백 무조건 1개 이상이어야 하기 때문에 포화 상태로 인식하고 데이터를 넣지 않는다.
- front= (front + 1) % size만큼 움직입니다.
- 공간이 남았기 때문에 데이터 추가 가능하다.

큐의 활용 예시
- 대기 번호표
- 물품 진열
- BFS 구현
- 프린터 출력 처리
- 콜센터 고객 대기시간
힙
힙의 개념
- 완전 이진트리의 일종 (여러 값 중, 최댓값과 최솟값을 빠르게 찾아내도록 만들어진 자료구조)
- 우선순위 큐를 위해 만들어진 자료구조
- 일종의 트리로 여러 개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조
- 빅오 : O(logn)
* 우선 순위 큐
- 데이터들이 우선순위를 가지고 있고, 우선순위가 높은 데이터가 먼저 나간다.
- CPU 작업 스케줄링, 시뮬레이션 시스템에서 사용
힙의 종류
- 최대 힙(max heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진트리
- key(부모 노드) ≥ key(자식 노드)
- 최소 힙(min heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진트리
- key(부모 노드) ≤ key(자식 노드)
힙 특징
- 힙을 저장하는 표준적인 자료구조는 배열이다.
- 중복 값을 허용한다.
- 반 정렬 상태를 유지한다.
힙의 연산
- 삽입
- 힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 삽입
- 새로운 노드를 부모 노드들과 교환
- 삭제
- 최대 힙에서 최댓값은 루트 노드이므로 루트 노드가 삭제됨 (최대 힙에서 삭제 연산은 최대값 요소를 삭제하는 것)
- 삭제된 루트 노드에는 힙의 마지막 노드를 가져옴
- 힙을 재구성
참조
공통
https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer Science/Data Structure/Stack %26 Queue.md
스택
https://gmlwjd9405.github.io/2018/08/03/data-structure-stack.html
https://monsieursongsong.tistory.com/4
http://www.tcpschool.com/java/java_collectionFramework_stackQueue
큐
https://monsieursongsong.tistory.com/5
https://velog.io/@riceintheramen/Stack-Queue-3
힙
https://gmlwjd9405.github.io/2018/05/10/data-structure-heap.html
반응형
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] Array vs List, ArrayList vs LinkedList (0) | 2020.12.29 |
|---|